在java领域,并发编程一直是一个具有挑战性的技术,本文将给大家介绍一下volatile的原理。
1. 理清几个概念
A . 共享变量:共享变量是指可以同时被多个线程访问的变量,共享变量是被存放在堆里面,所有的方法内临时变量都不是共享变量。
B . 重排序:重排序是指为了提高指令运行的性能,在编译时或者运行时对指令执行顺序进行调整的机制。重排序分为编译重排序和运行时重排序。编译重排序是指编译器在编译源代码的时候就对代码执行顺序进行分析,在遵循as-if-serial的原则前提下对源码的执行顺序进行调整。as-if-serial原则是指在单线程环境下,无论怎么重排序,代码的执行结果都是确定的。运行时重排序是指为了提高执行的运行速度,系统对机器的执行指令的执行顺序进行调整。
C . 可见性:内存的可见性是指线程之间的可见性,一个线程的修改状态对另外一个线程是可见的,用通俗的话说,就是假如一个线程A修改一个共享变量flag之后,则线程B去读取,一定能读取到最新修改的flag。
说到这里,有些同学可能会觉得上述C说的这不是废话么,线程A修改变量flag后,线程B肯定是可以拿到最新的值。假如你真的这么认为,那就大错特错了,运行下面一段代码:
1 | public class VariableTest { |
运行结果: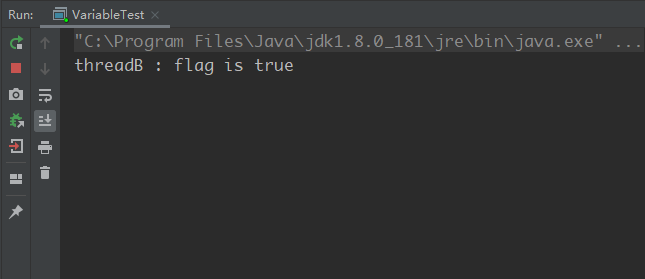
以上运行结果证明:线程B修改变量flag之后,线程A读取不到最新的值,A线程一直在运行,无法停止。
2. 分析上述现象的原因
造成上述现象的根本原因就是A和B两个线程的内存相互之间是不可见的,造成不可见的原因有二:
A . cache机制导致内存不可见
CPU的运行速度是远远高于内存的读写速度的,为了不让cpu为了等待读写内存数据,现代cpu和内存之间都存在一个高速缓存cache(实际上是一个多级寄存器),如下图:
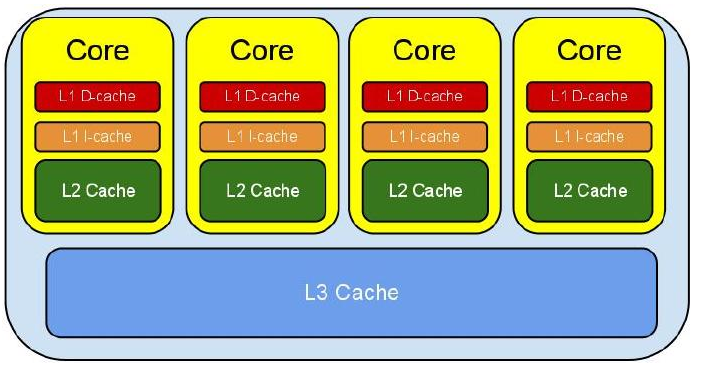
线程在运行的过程中会把主内存的数据拷贝一份到线程内部cache中,也就是working memory。这个时候多个线程访问同一个变量,其实就是访问自己的内部cache。
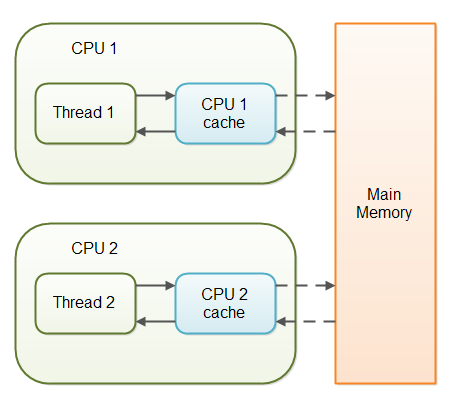
所以说,上面例子出现问题的原因在于:线程A把变量flag加载到自己的内部缓存cache中,线程B修改变量flag后,即使重新写入主内存,但是线程A不会重新从主内存加载变量flag,看到的还是自己cache中的变量flag。所以线程A是读取不到线程B更新后的值。
除了cache的原因,还有一个因素会导致内存不可见:
B . 重排序后的指令在多线程执行时也有可能导致内存不可见,由于指令顺序的调整,线程A读取某个变量的时候线程B可能还没有进行写入操作,虽然代码顺序上写操作是在前面的。
3. volatile原理
volatile修饰的变量不允许线程内部cache缓存和重排序,线程读取数据的时候直接读写内存,同时volatile不会对变量加锁,因此性能会比synchronized好。另外还有一个说法是使用volatile的变量依然会被读到各自的cache中,只不过当B线程修改了flag之后,会将flag写回主内存,同时会通过信号机制通知到A线程去同步内存中flag的值。我个人更倾向于后者的解释,还望大神指导一下正确的答案。
但是,volatile不保证操作的原子性,请勿使用volatile来进行原子性操作。
4. 总结
在 Java 中 volatile、synchronized 和 final 实现可见性。
在 Java 中 synchronized 和 lock、unlock 操作保证原子性。
volatile的性能:
volatile 的读性能消耗与普通变量几乎相同,但是写操作稍慢,因为它需要在本地代码中插入许多内存屏障指令来保证处理器不发生乱序执行。
一个被volatile声明的变量主要有以下两种特性保证保证线程安全:
- 可见性。
- 有序性。
volatile 真的能够保证一个变量在多线程环境下都能被正确的使用吗?
答案是否定的。原因是因为Java里面的运算并非都是原子操作。

