YARN是一种新的 Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
一、YARN中的核心概念
ResourceManager
ResourceManager是master上的进程,负责整个分布式系统的资源管理和调度。
作用:
- 处理来自client端的请求(包括提交作业/杀死作业);
- 启动/监控Application Master;
- 监控NodeManager的情况,比如可能挂掉的NodeManager。
NodeManager
NodeManager是处在slave节点上的进程,他只负责当前slave的资源管理和调度,以及task的运行。
作用:
- 定期向ResourceManager汇报资源/Container的情况(heartbeat);
- 接受来自ResourceManager对于Container的启停命令。
Application Master
每一个提交到集群的作业都会有一个与之对应的Application Master来负责应用程序的管理。
作用:
- 负责进行数据切分;
- 为当前应用程序向ResourceManager去申请资源(也就是Container),并分配给具体的任务;
- 与NodeManager通信,用来启停具体的任务,任务运行在Container中;
- 任务的监控和容错也是由Application Master来负责的。
Container
包含了Application Master向ResourceManager申请的计算资源,比如说CPU/内存的大小,以及任务运行所需的环境变量和队任务运行情况的描述。AM也是在Container上运行的,不过AM的Container是RM申请的。
理解重点:
- Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。
- Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster。
- Container的运行是由ApplicationMaster向资源所在的NodeManager发起的,Container运行时需提供内部执行的任务命令(可以是任何命令,比如java、Python、C++进程启动命令均可)以及该命令执行所需的环境变量和外部资源(比如词典文件、可执行文件、jar包等)。
另外,由上述的AM也是在Container上运行的,不过AM的Container是RM申请的这句话可以得出一个应用程序所需的Container分为两大类,如下:
- 运行ApplicationMaster的Container:这是由ResourceManager(向内部的资源调度器)申请和启动的,用户提交应用程序时,可指定唯一的ApplicationMaster所需的资源;
- 运行各类任务的Container:这是由ApplicationMaster向ResourceManager申请的,并由ApplicationMaster与NodeManager通信以启动之。
注意:以上两类Container可能运行在任意节点上,它们的位置通常而言是随机的,即ApplicationMaster可能与它管理的任务运行在同一个节点上。
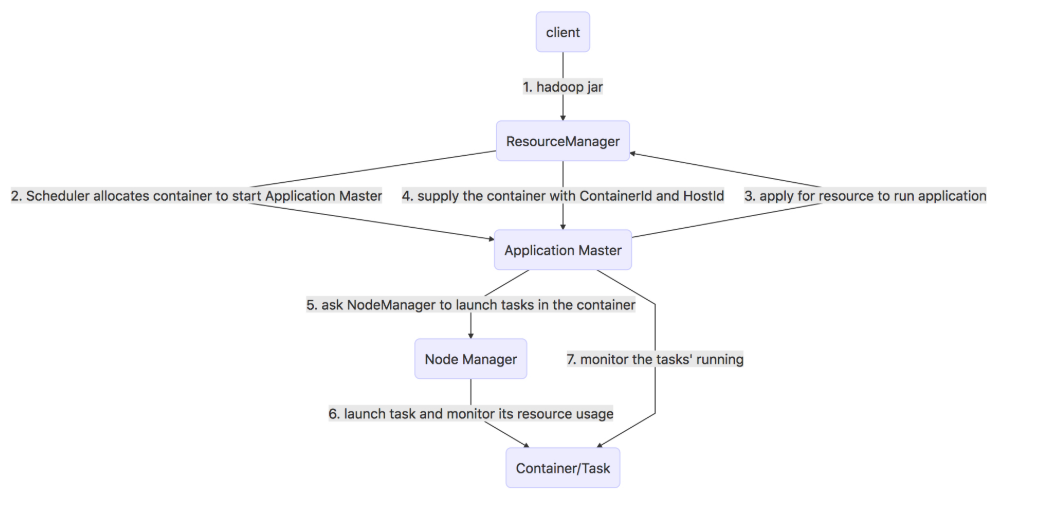
二、YARN工作原理
- Client端提交应用程序到RM,其中包括AM程序、启动AM命令、用户程序等 。
- RM接收到请求后为该作业分配一个Container(这个Container是如上两种的第一种),并与NM进行通信,要求NM在刚刚分配好的Container中启动应用程序的AM。
- AM首先会向RM注册,这样用户就可以直接通过RM查看任务运行的状态,而后RM会为各个任务申请资源,并监控运行情况,直到运行结束,即重复4~7步骤。
- AM采用轮询(polling)的方式通过RPC协议向RM申请并领取资源(此处领取的资源是第二种Container)。
- 一旦AM申请到资源后,便与对应的NM通信,要求它启动任务。
- NM为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各个任务通过RPC协议向AM汇报自己的状态和进度,以让AM随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向AM查询应用程序的当前运行状态。
- 应用程序运行完成后,AM向RM注销并关闭自己 。
流程图如下所示:
三、YARN的通信协议
jobclient(作业提交客户端)与RM之间的协议 - ApplicationClientProtocol
jobclient通过该RPC协议提交应用程序、查询应用程序状态等 。
admin(管理员)与RM之间的通信协议 - ResourceManagerAdministration Protocol
admin通过该RPC协议更新系统配置文件,比如节点黑白名单、用户队列权限等 。
AM与RM之间的协议 - ApplicationMasterProtocol
AM通过该RPC协议向RM注册和撤销自己,并为各个任务申请资源 。
AM与NM之间的协议 - ContainerManagementProtoocl
AM通过该RPC要求NM启动或者停止container,获取各个container的使用状态等信息 。
NM与RM之间的协议 - ResourceTracker
NM通过该RPC协议向RM注册,并定时发送心跳信息汇报当前节点的资源使用情况和container运行情况 。
四、YARN三种调度器的详细介绍
1.FIFO Scheduler
1.1 定义
将所有的Applications放到队列中,先按照作业的优先级高低、再按照到达时间的先后,为每个app分配资源。如果第一个app需要的资源被满足了,如果还剩下了资源并且满足第二个app需要的资源,那么就为第二个app分配资源;如果没有剩下,那么第二个app一直等待第一个app执行完毕。
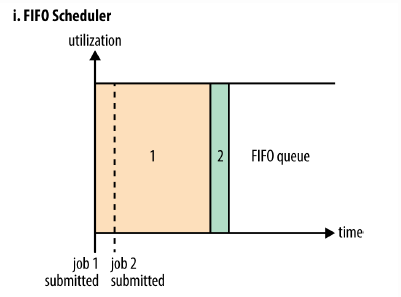
上图示例:有一个很大的job1,它先提交,并且占据了全部的资源。那么job2提交时发现没有资源了,则job2必须等待job1执行结束,才能获得资源执行。
1.2 优缺点
优点:简单,不需要配置。
缺点:不适合共享集群。如果有大的app需要很多资源,那么其他app可能会一直等待。
1.3 配置
FIFO Scheduler不需要配置。
2.Capacity Scheduler (YRAN默认的调度器)
2.1 定义
CapacityScheduler用于一个集群(集群被多个组织共享)中运行多个Application的情况,目标是最大化吞吐量和集群利用率。CapacityScheduler允许将整个集群的资源分成多个部分,每个组织使用其中的一部分,即每个组织有一个专门的队列,每个组织的队列还可以进一步划分成层次结构(Hierarchical Queues),从而允许组织内部的不同用户组的使用。每个队列内部,按照FIFO的方式调度Applications。当某个队列的资源空闲时,可以将它的剩余资源共享给其他队列。集群资源按照队列为单位进行划分。
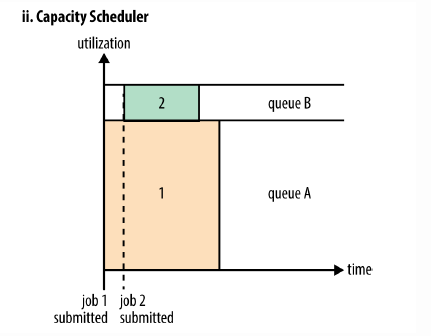
上图示例:有一个专门的队列允许小的apps提交之后能够尽快执行,注意到job1先提交,先执行时并没有占用系统的全部资源(假如job1需要100G内存,但是整个集群只有100G内存,那么只分配给job1 80G),而是保留了一部分的系统资源。
2.2 优缺点
对于Capacity调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
2.3 配置
1 |
|
说明:
- root队列下面有两个队列,分别为prod(40%的容量,即使用40%的集群资源)和dev(60%的容量,最大的75%,说明即使prod队列空闲了,那么dev最多只能使用75%的集群资源。这样就可以保证prod中添加新的apps时马上可以使用25%的资源)。
- 除了队列的容量和层次,还可以指定单个用户或者应用被分配的资源大小、同时可以运行的app数量、队列的ACLs。
- 可以指定app要放在哪个队列中。如果不指定,app将会被放在名字是 default的队列中。
- CapacityScheduler的队列名字必须是层次结构最后的名字,比如eng。不能是root.dev.eng或者dev.eng。
配置步骤
- 关闭yarn,stop-yarn.sh
- 先备份原来的capacity-scheduler.xml: cp capacity-scheduler.xml capacity-scheduler.xml.bak,然后编辑新的capacity-scheduler.xml文件内容如上。
- 将该文件发送到集群中的其他机器中,用scp即可。
- 启动yarn,start-yarn.sh
- 通过WebUI查看配置是否成功,即8088页面的Cluster->Scheduler。
- 在DistributedCount.java中MapReduce程序指定队列运行
job.getConfiguration().set("mapreduce.job.queuename", "eng");运行中可以通过WebUI可以查看运行过程。
3.Fair Scheduler
3.1 定义
Fair Scheduler允许应用在一个集群中公平地共享资源。默认情况下FairScheduler的公平调度只基于内存,也可以配置成基于memory and CPU。当集群中只有一个app时,它独占集群资源。当有新的app提交时,空闲的资源被新的app使用,这样最终每个app就会得到大约相同的资源。可以为不同的app设置优先级,决定每个app占用的资源百分比。FairScheduler可以让短的作业在合理的时间内完成,而不必一直等待长作业的完成。
Fair Sharing: Scheduler将apps组织成queues,将资源在这些queues之间公平分配。默认情况下,所有的apps都加入到名字为“default“的队列中。app也可以指定要加入哪个队列中。队列内部的默认调度策略是基于内存的共享策略,也可以配置成FIFO和multi-resource with Dominant Resource Fairness。
Minimum Sharing:FairScheduller提供公平共享,还允许指定minimum shares to queues,从而保证所有的用户以及Apps都能得到足够的资源。如果有的app用不了指定的minimum的资源,那么可以将超出的资源分给别的app使用。
FairScheduler默认让所有的apps都运行,但是也可以通过配置文件小智每个用户以及每个queue运行的apps的数量。这是针对一个用户一次提交hundreds of apps产生大量中间结果数据或者大量的context-switching的情况。
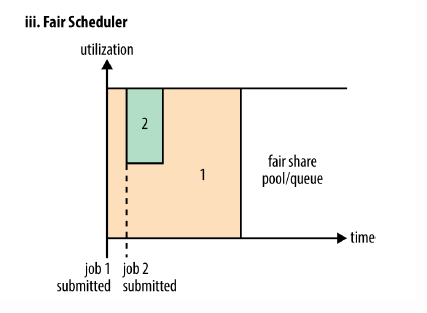
上图示例:大的任务job1提交并执行,占用了集群的全部资源,开始执行。之后小的job2执行时,获得系统一半的资源,开始执行。因此每个job可以公平地使用系统的资源。当job2执行完毕,并且集群中没有其他的job加入时,job1又可以获得全部的资源继续执行。
注意:job2提交之后并不能马上就获取到集群一半的资源,因为job2必须等待job1释放containers。
下图:Fair Sharing between user queues
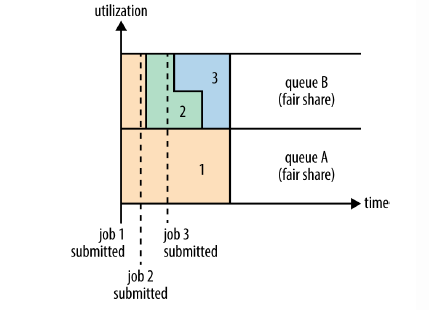
上图示例:两个用户A和B。A提交job1时集群内没有正在运行的app,因此job1独占集群中的资源。用户B的job2提交时,job2在job1释放一半的containers之后,开始执行。job2还没执行完的时候,用户B提交了job3,job2释放它占用的一半containers之后,job3获得资源开始执行。
3.3 配置
一个简单的公平调度器配置如下:
1 |
|
配置步骤
相比Capacity Scheduler的配置步骤多了一步,就是需要在第二步之前做如下操作:
在yarn-site.xml文件中配置如下内容开启fair机制。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
> <description>The class to use as the resource scheduler.</description>
> <name>yarn.resourcemanager.scheduler.class</name>
> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
> </property>
>
> <property>
> <name>yarn.scheduler.fair.allocation.file</name>
> <value>/home/hadoop/etc/hadoop/fairscheduler.xml</value>
> </property>
>
> <!-- 当queue占用的资源大于它应得的,那么调度器可以杀掉queue对应的containers -->
> <property>
> <name>yarn.scheduler.fair.preemption</name>
> <value>true</value>
> </property>
>
4. Fair Scheduler和Capacity Scheduler的异同
同
- 以队列划分资源
- 设定最低保证和最大使用上限
- 在某个队列空闲时可以将资源共享给其他队列。
异
- 资源公平共享:在每个队列中,Fair Scheduler可选择按照FIFO、Fair或DRF策略为应用程序分配资源。Fair策略即平均分配,默认情况下,每个队列采用该方式分配资源
- 支持资源抢占:当某个队列中有剩余资源时,调度器会将这些资源共享给其他队列,而当该队列中有新的应用程序提交时,调度器要为它回收资源。为了尽可能降低不必要的计算浪费,调度器采用了先等待再强制回收的策略,即如果等待一段时间后尚有未归还的资源,则会进行资源抢占;从那些超额使用资源的队列中杀死一部分任务,进而释放资源
- 负载均衡:Fair Scheduler提供了一个基于任务数的负载均衡机制,该机制尽可能将系统中的任务均匀分配到各个节点上。此外,用户也可以根据自己的需求设计负载均衡机制
- 调度策略灵活配置:Fiar Scheduler允许管理员为每个队列单独设置调度策略(当前支持FIFO、Fair或DRF三种)
- 提高小应用程序响应时间:由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成
5. 总结:三种调度策略对比
- FIFO Scheduler分配资源的顺序和提交应用程序的顺序相同,不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。
- Capacity Scheduler中,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
- Fair Scheduler中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。
五、Container资源参数
1 | 参数 默认值 |
内存配置
- yarn.nodemanager.resource.memory-mb默认值为-1,代表着YARN的NodeManager占总内存的80%。也就是说假如我们的机器为64GB内存,出去非YARN进程需要的20%内存,我们大概需要64*0.8≈51GB,在分配的时候,单个任务可以申请的默认最小内存为1G,任务量大的话可最大提高到8GB。
- 在生产场景中,简单的配置,一般情况下:yarn.nodemanager.resource.memory-mb直接设置成我们需要的值,且要是最大和最小内存需求的整数倍;(一般Container容器中最小内存为4G,最大内存为16G)。
- 假如64GB的机器内存,我们有51GB的内存可用于NodeManager分配,根据上面的介绍,我们可以直接将yarn.nodemanager.resource.memory-mb值为48GB,然后容器最小内存为4GB,最大内存为16GB,也就是在当前的NodeManager节点下,我们最多可以有12个容器,最少可以有3个容器。
CPU配置
- 此处的CPU指的是虚拟的CPU(CPU virtual core),之所以产生虚拟CPU(CPU vCore)这一概念,是因为物理CPU的处理能力的差异,为平衡这种差异,就引入这一概念。
- yarn.nodemanager.resource.cpu-vcores表示能够分配给Container的CPU核数,默认配置为-1,代表值为8个虚拟CPU,推荐该值的设置和物理CPU的核数数量相同,若不够,则需要调小该值。
- yarn.scheduler.minimum-allocation-vcores的默认值为1,表示每个Container容器在处理任务的时候可申请的最少CPU个数为1个。
- yarn.scheduler.maximum-allocation-vcores的默认值为4,表示每个Container容器在处理任务的时候可申请的最大CPU个数为4个。

